The file contains data on 5000 customers of Universal Bank.
The data include customer demographic information (age, income, etc.), the customer's relationship with the bank (mortgage, securities account, etc.), and the customer response to the last personal loan campaign (Personal Loan). Among these 5000 customers, only 480 (= 9.6%) accepted the personal loan that was offered to them in the earlier campaign. In this exercise we focus on two predictors: Online (whether or not the customer is an active user of online banking services) and Credit Card (abbreviated CC below) (does the customer hold a credit card issued by the bank), and the outcome Personal Loan (abbreviated Loan below).
Partition the data into training (60%) and validation (40%) sets.
Table gives the pivot table for the training data with Online as a column variable, CC as a row variable, and Loan as a secondary row variable. The values inside the cells should convey the count (how many records are in that cell).
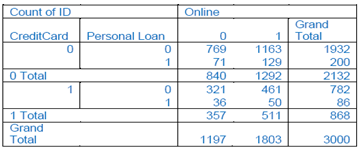
1) Consider the task of classifying a customer that owns a bank credit card and is actively using online banking services. Looking at the pivot table, what is the probability that this customer will accept the loan offer? (This is the probability of loan acceptance (Loan=1) conditional on having a bank credit card (CC=1) and being an active user of online banking services (Online=1)).
2) Given the two separate pivot tables for the training data. Table 2 has Loan (rows) as a function of Online (columns) and Table 3 has Loan (rows) as a function of CC.

Table 2: Pivot tables for the training data: Loan (rows) as a function of Online (columns)
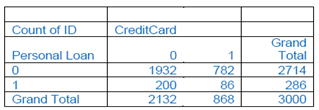
Table 3: Pivot tables for the training data: Loan (rows) as a function of CC.
Compute the following quantities (P(A|B) means "the probability of A given B"):
i. P(CC = 1|Loan = 1) (the proportion of credit card holders among the loan acceptors)
ii. P(Online = 1|Loan = 1)
iii. P(Loan = 1) (the proportion of loan acceptors)
iv. P(CC = 1|Loan = 0)
v. P(Online = 1|Loan = 0)
vi. P(Loan = 0)
3) Use the quantities computed above to compute the naive Bayes probability:
P(Loan = 1|CC = 1; Online = 1)
4) Compare this value with the one obtained from the crossed pivot table in question 1). Which is a more accurate estimate?
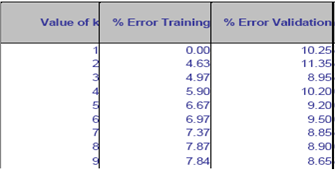
5) Given the following table 4 as an output of XLMiner using KNN technique, what is a choice of k that balances between overfitting and ignoring the predictor information? Justify your answer.